Accessing and Downloading TCGA Data
Learning objectives
Learners will
- Discover public resources for accessing, analyzing, and downloading TCGA data.
- Learn about features of the NCI Genomic Data Commons Data Portal.
- Understand how to download TCGA data from the GDC.
What is TCGA?
The Cancer Genome Atlas (TCGA) was a large scale and collaborative effort, organized by the National Cancer Institute (NCI) and the National Human Genome Research Institute (NHGRI) in 2006, to improve our understanding of cancer at the molecular level using genomics. This effort resulted in a massive (~2.5 petabytes) and largely open-source dataset comprised of genomic, epigenomic, transcriptomic, and proteomic data combined with rich clinical information and related metadata from over 11,000 patients representing 33 cancer types.
Data types
Data collected for a specific case in TCGA may have differed according to sample quality and quantity, cancer type, or technology available at the time of analysis. --- https://www.cancer.gov/ccg/research/genome-sequencing/tcga/using-tcga-data/types.
Samples of the following types were collected from patients (cases): primary solid tumors, recurrent solid tumors, blood derived normal and tumor, metastatic, and solid tissue normal, among others.
3 major types of data were collected:
-
clinical information (e.g., demographic information, treatment information, survival data, pathology images).
Note
Radiological images are located in the Cancer Imaging Archive.
-
molecular analyte data (e.g., sample portion weight)
-
molecular characterization data (e.g., exome (variant analysis), single nucleotide polymorphism (SNP), DNA methylation, transcriptome (mRNA), microRNA (miRNA), and proteome).
Note
Proteomic data is stored within The Cancer Proteome Atlas Portal.
For a table summary of data types in TCGA, see here.
Open Access vs Controlled Access Data
Not all data in TCGA is open access. Data unique to an individual (e.g., individual germline variant data (SNP .cel files), primary sequence data (.bam files), clinical free text files, and Exon array files) are considered controlled access data, which requires user certifaction through NCBI's database of Genotypes and Phenotypes (dbGAP) Authorized Access.
Find more detailed instructions on accessing controlled data here.
The primary hub for TCGA data including supplemental data and associated files from resulting publications is the Genomic Data Commons. There is also a suite of other tools that have been developed to analyze TCGA data, which are listed here and here. Some of these will be discussed more in detail below.
Confusing Nomenclature
Like many large projects, there are variations of data available. Let's clear up some confusion and define the following:
-
Harmonized data
- Data aligned to GRCh38 and data further proccessed using standard pipelines featuring open-source tools. These data are available in the GDC.
-
Legacy data (Firehose Legacy Data)
-
Refers to the original mutation data generated by the individual TCGA sequencing centers. These data (level 3 and level 4) can be found in the Broad's Firehose. These data are similar but not the same as the original publication data, which usually underwent additional filtering. TCGA data associated with publications can be found using the GDC Publication Pages or cBioPortal.
-
See Gao et al. 2019 for a comparison of legacy vs harmonized TCGA data.
-
-
TCGA Pan-Cancer Atlas data
What is the GDC?
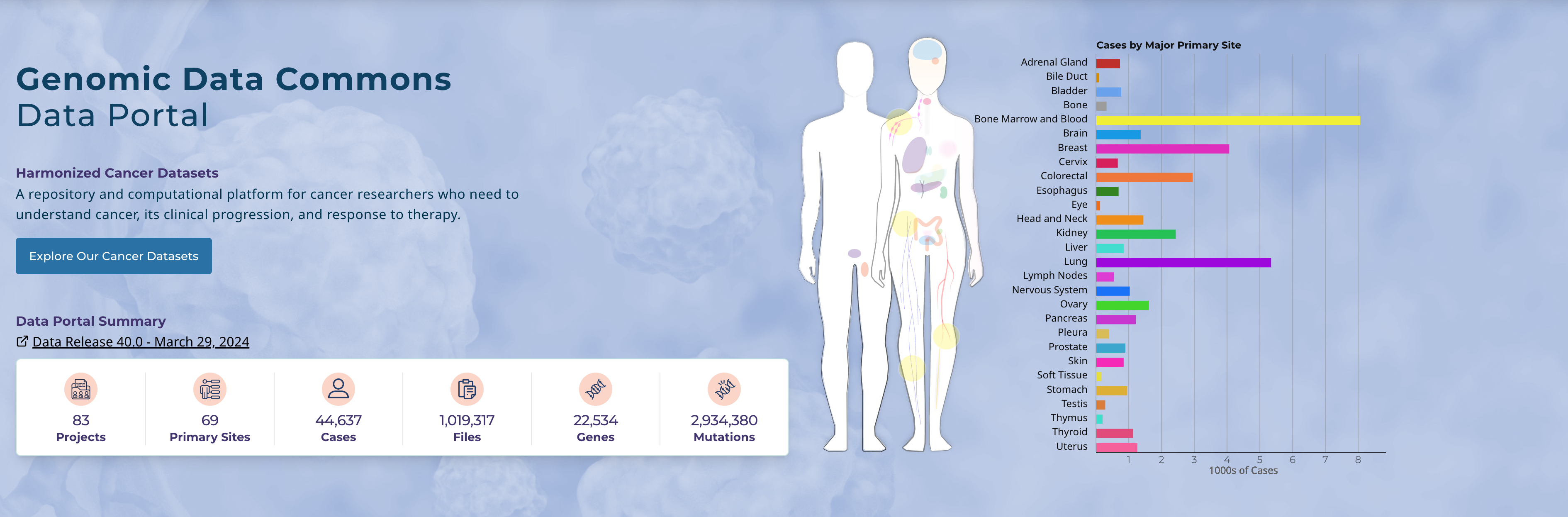
The Genomic Data Commons (GDC) is a repository and computational resource for cancer genomic data and associated clinical and related information. The GDC includes data from 22 programs (including TCGA), 83 projects, 69 primary sites, and 44,637 cases. Genomic data in the GDC have been harmonized or processed in the same way. All sequence data have been aligned using GRCh38 and further proccessed using standard pipelines featuring open-source tools. For more information on the genomic data pipelines used, see https://gdc.cancer.gov/about-data/gdc-data-processing/genomic-data-processing.
Have questions about TCGA in the GDC?
Check out these frequently asked questions.
The GDC data portal can be used to submit, access, and analyze cancer genomic data. Data access and downloads are free and no logins are required unless further permissions are required (e.g., controlled data require dbGAP authorization - login with eRA commons).

The GDC workflow:
-
Build cohort
- Use the "Cohort Builder"
-
Download the data or analyze directly
TCGA data within GDC
The TCGA data within the GDC are harmonized. Use these resources to understand more about the data, including the many codes used.
Note
Legacy datasets, datasets not aligned to GRCh38, and data from the original sequencing centers, are no longer archived by the GDC. To obtain legacy data, you can use resources such as the Broad's GDAC Firehose (Firebrowse) or cBioPortal's DataHub.
GDC Analysis Tools
-
- Slice individual BAM files based on the variant, gene, position, or SNPs for individual cases/entities
- Download unmapped reads from a BAM file
-
- Visualize clinical data with histograms, survival plots, box and QQ plots
-
- compares the active cohort to another cohort; includes Venn diagrams and survival plots
-
- Search and select somatic Mutation Annotation Format (MAF) files to be aggregated, compressed, and downloaded.
-
- Create a heatmap with sample and gene clustering. Genes by default are the top variably expressed, but other gene sets can be used.
- View clustering by different metadata variables or select clusters of cases to define new cohorts.
- Explore lollipop and Circos plots.
-
- Find the most commonly mutated genes in a cohort.
- survival plot of patients with a given mutation compared to those without.
-
- Visualize the top most mutated cases and genes affected by high impact mutations in your cohort.
-
- Requires a login.
- Visualize read alignments from a BAM file.
-
- Compare gene and mutation sets and export based on overlaps.
- Can compare up to three cohorts.
Note
Figures and the data used to create figures can be exported directly from many of the analysis tools within the GDC.
When should you download TCGA data?
The GDC allows you to perform some analyses on cancer data spanning multiple programs and projects. You can perform similar tasks and other advanced tasks using other data platforms. However, you may want to download the data to explore further if:
- You are combining GDC data with your own data
- You are combining GDC data with data not found within the GDC
- You are performing more advanced analyses or analyses unavailable in the GDC or through other platforms
Steps to download data from the GDC
-
Navigate to the GDC Data Portal at https://portal.gdc.cancer.gov/
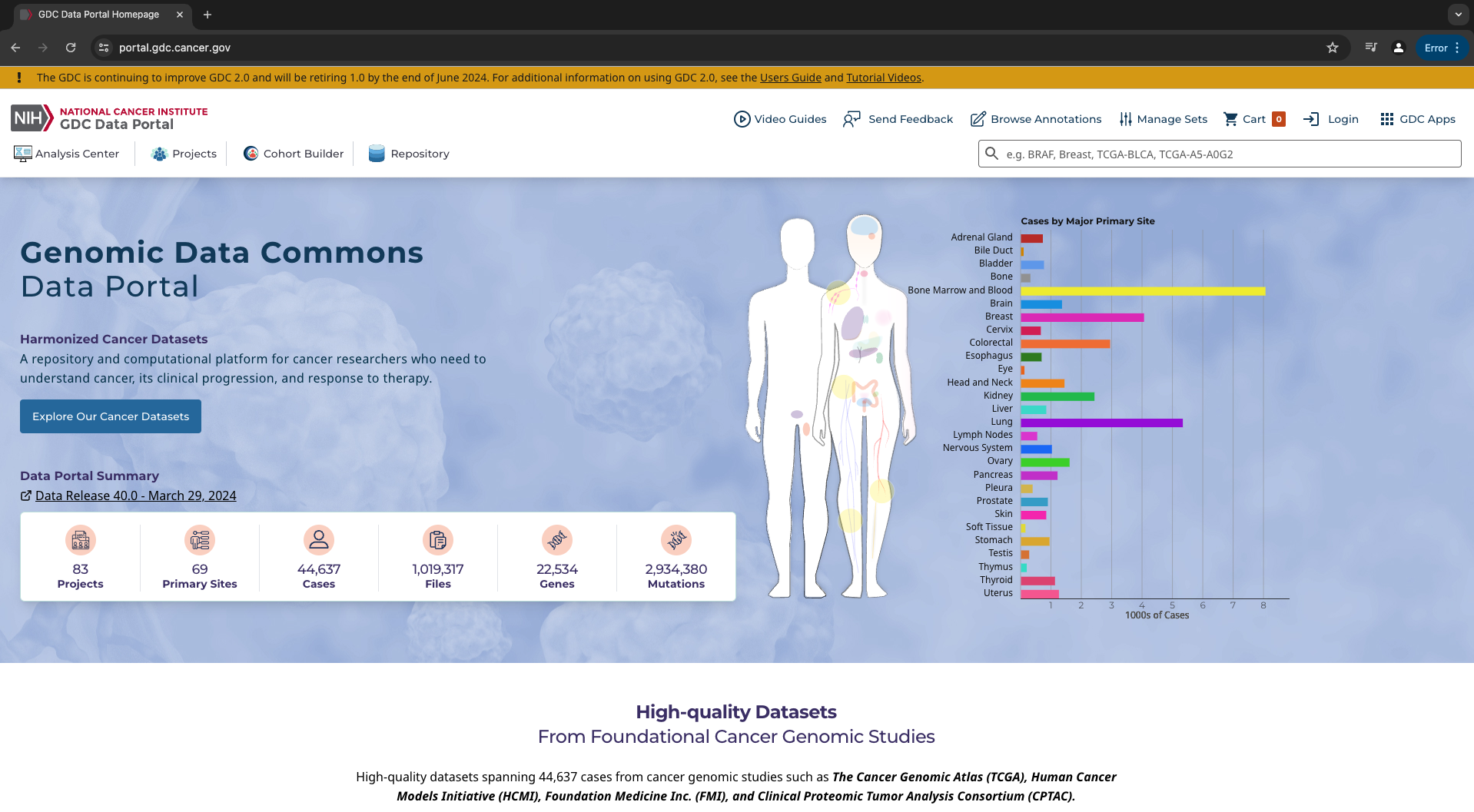
-
To select your cases of interest, you can navigate to "Projects" or "Cohort Builder"
Let's use breast cancer as an example. We will navigate to "Projects" and select "TCGA" in the "Programs" field. We will then select "TCGA-BRCA" in the resulting list. "BRCA" is the study abbreviation for breast invasive carcinoma.
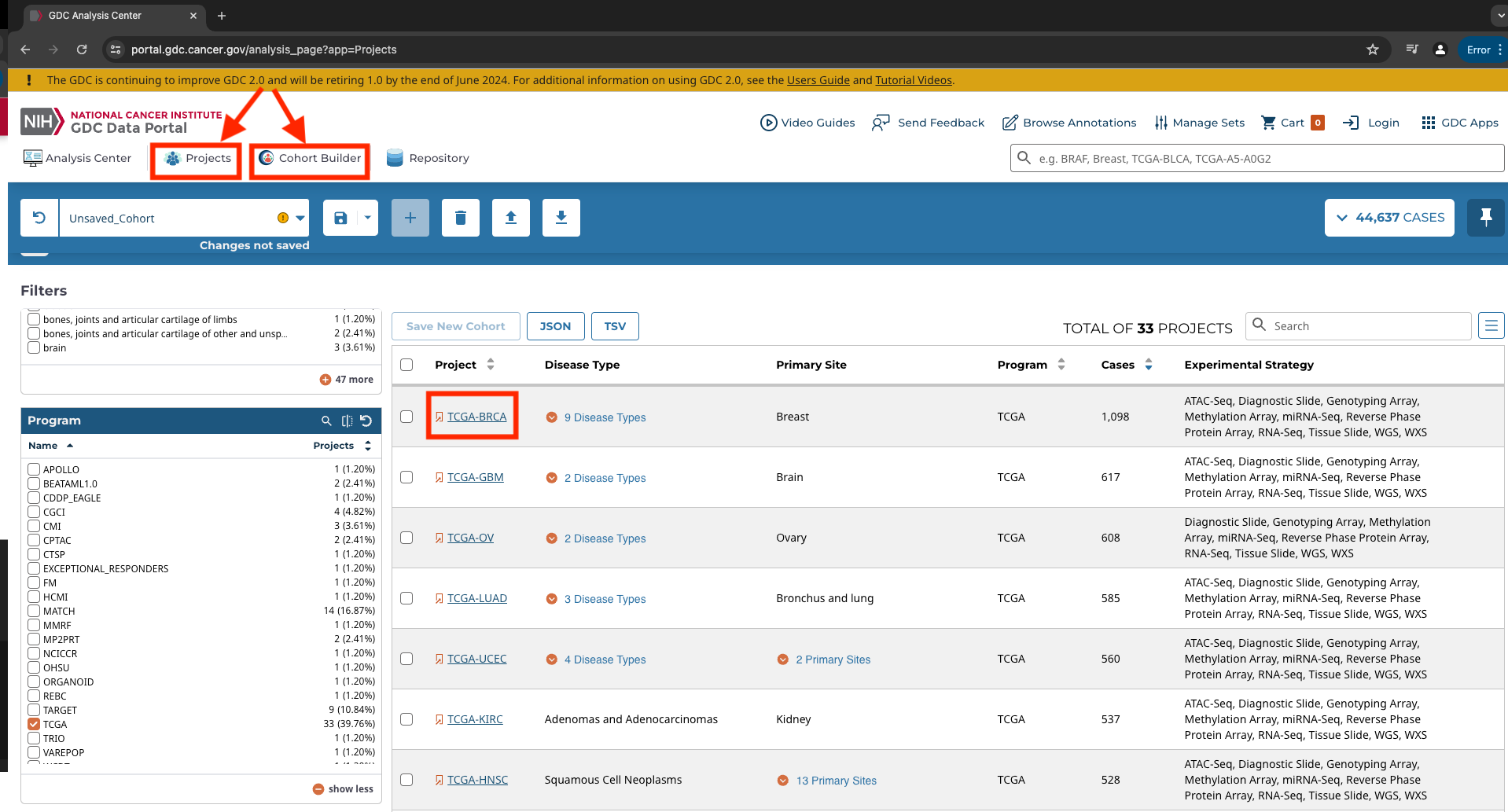
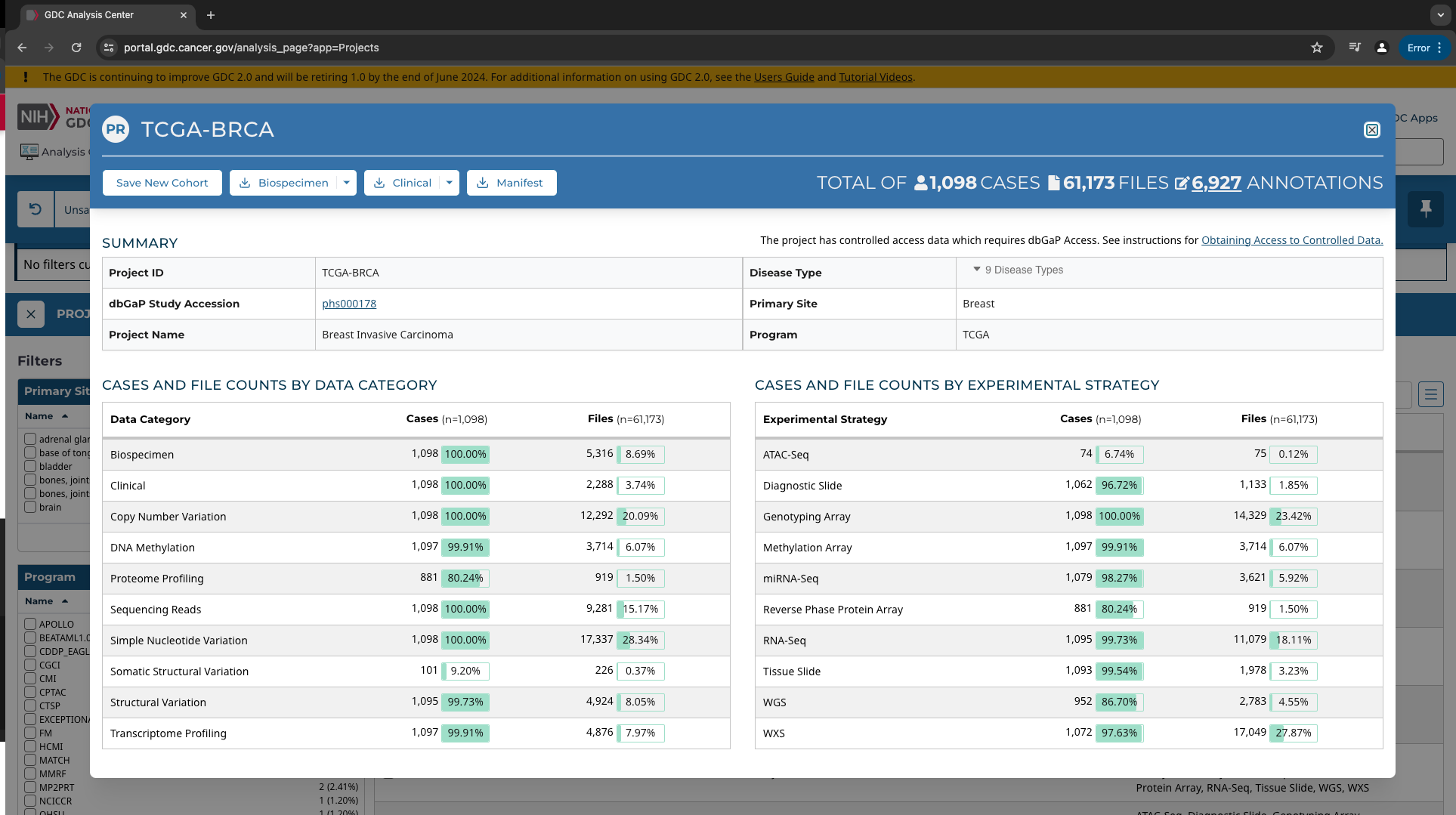
If you click on the project, you can view more summary information regarding the project.
Data Dictionary
You can use the "Data Dictionary Viewer" to identify fields of interest for selecting cases or data types.
-
Save our selection to a new cohort.
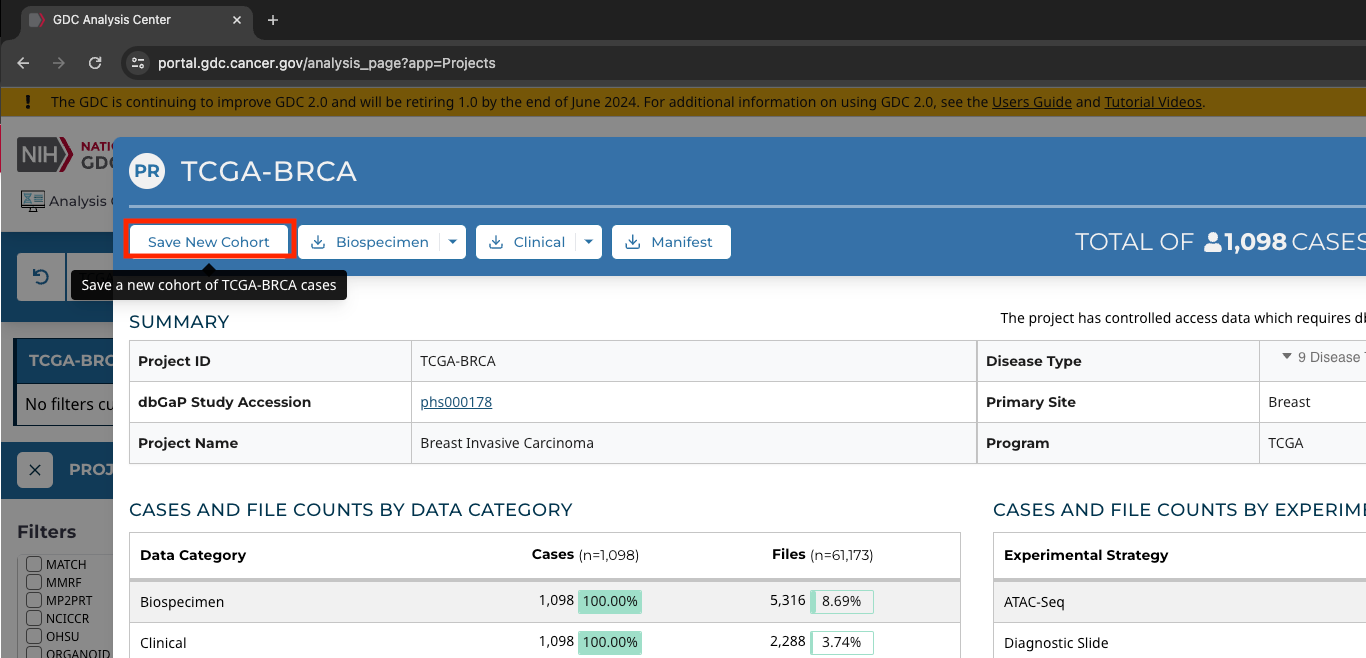
-
We can eliminate additional cases should we choose using "Cohort Builder". For example, let's select only "male subjects".
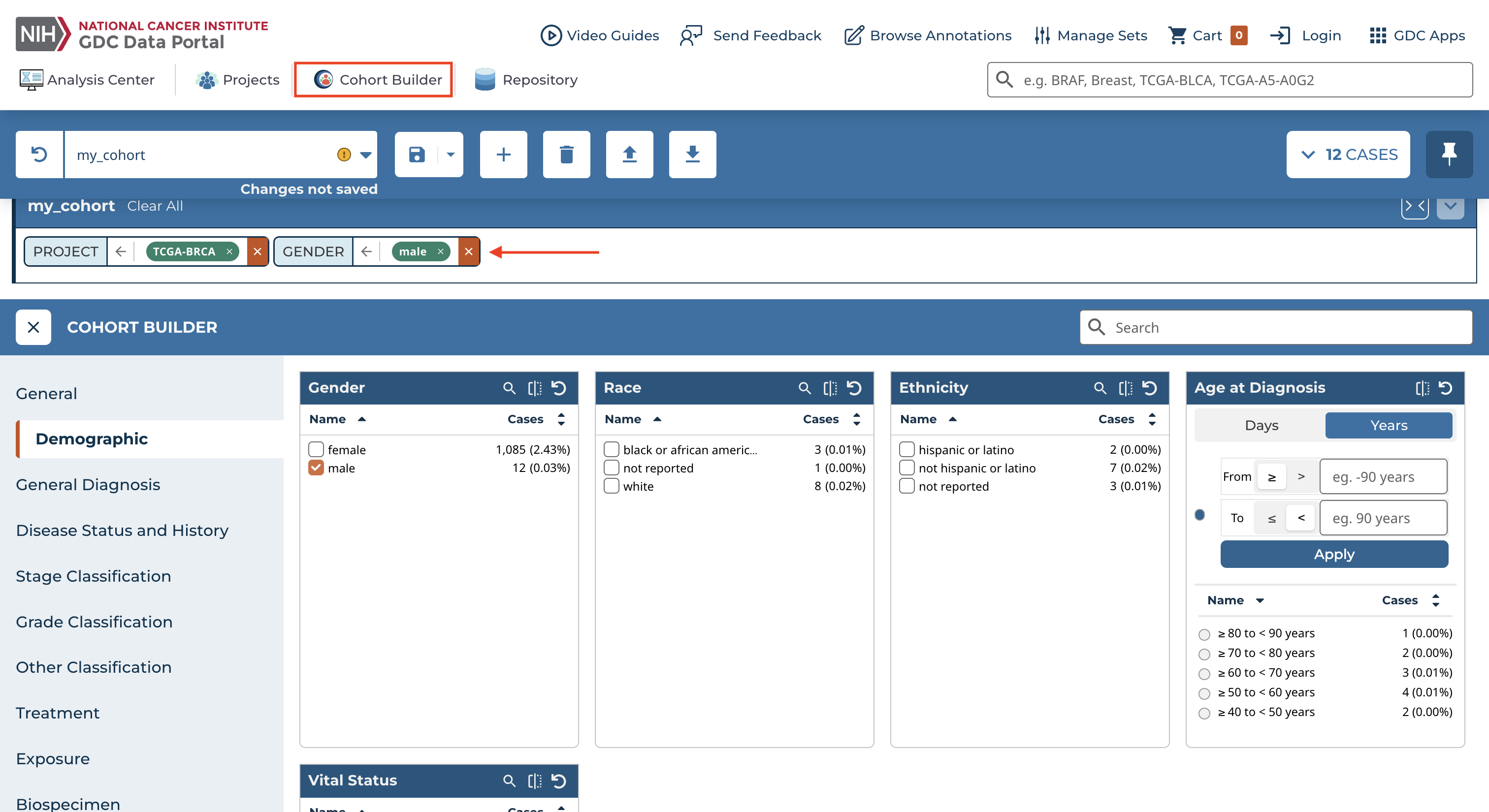
Notice that information about applied filters is displayed at the top of the page under the name of the cohort (e.g., my_cohort).
-
To download associated files, we can navigate to the "Repository". The "Respository" is used to filter files, whereas the "Cohort builder" is used to filter cases.
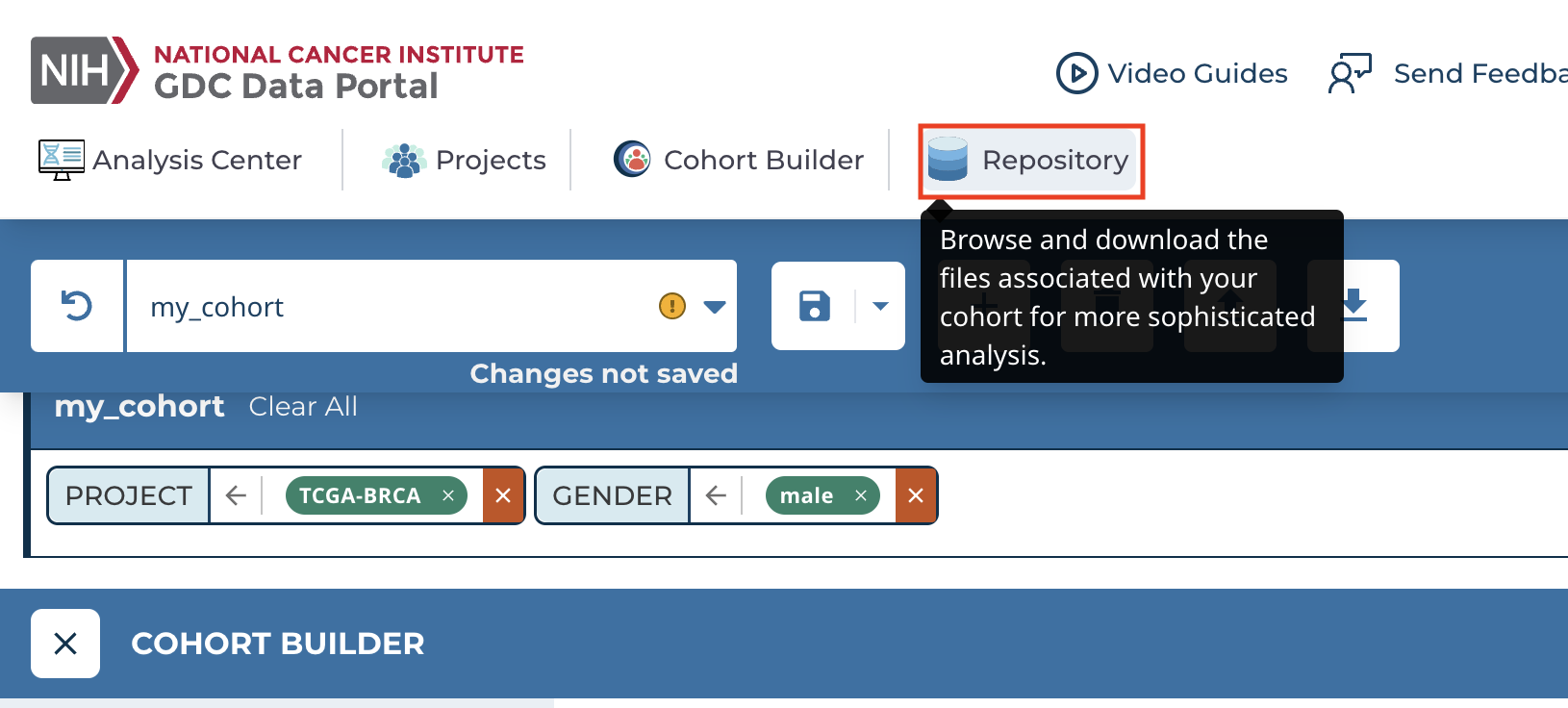
Note
We could have navigated to the data "Repository" from the beginning and applied quick filtering using "Cohort Summary Charts".

-
Once in the "Repository", the filters can be used to select the files we want to download. For example, we can choose RNA-Seq files and gene quantification files.
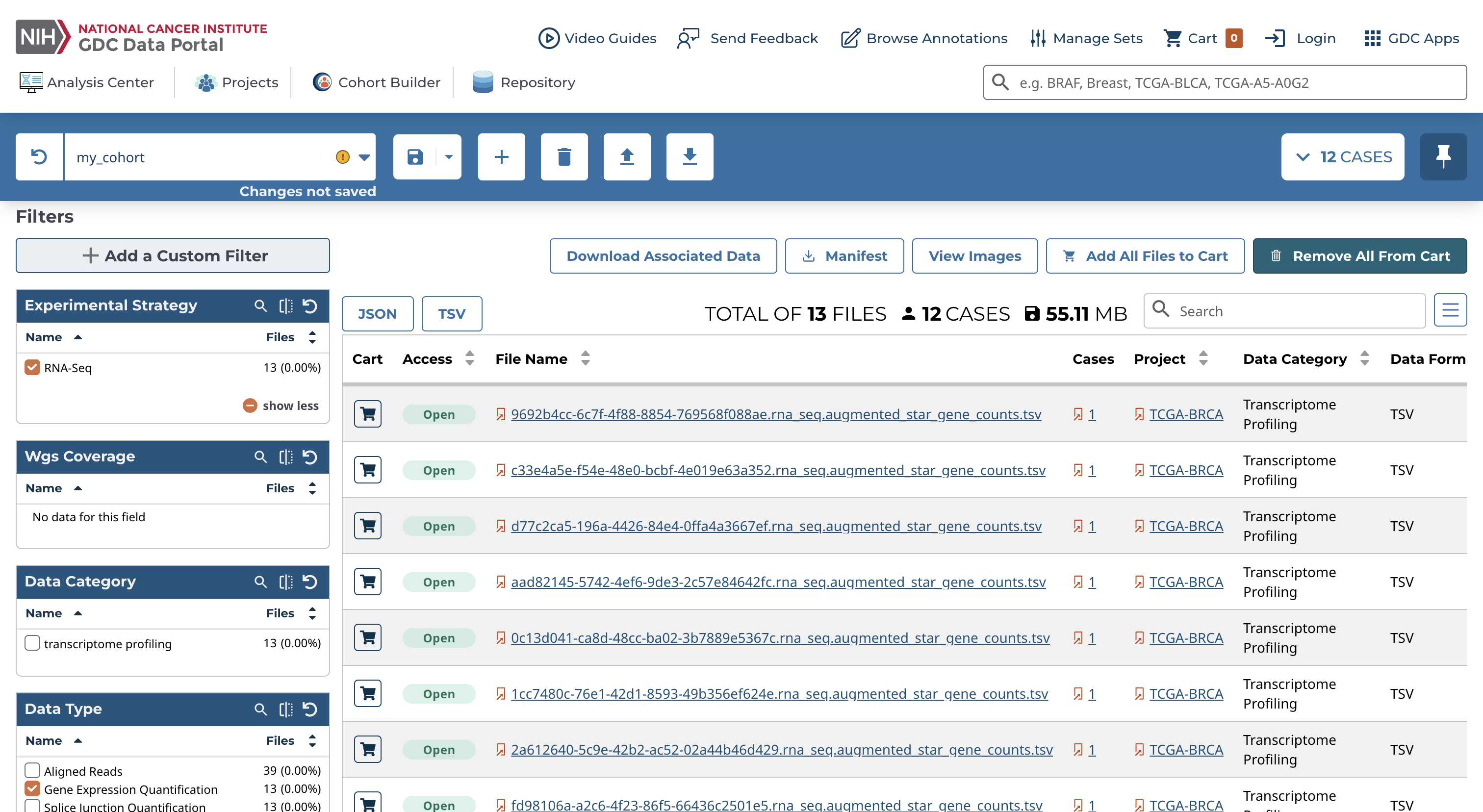
The "Files Table" provides information about each of the files. You can select a file to learn more about it, such as file properties, associated cases, and how the file was generated or processed. The same can be done regarding a specific case. The three bar icon to the right of the table allows you to add additional columns to the "Files Table" for easy viewing.
-
We can add files to the cart one by one using the cart icon or all at once using "Add All Files to Cart".
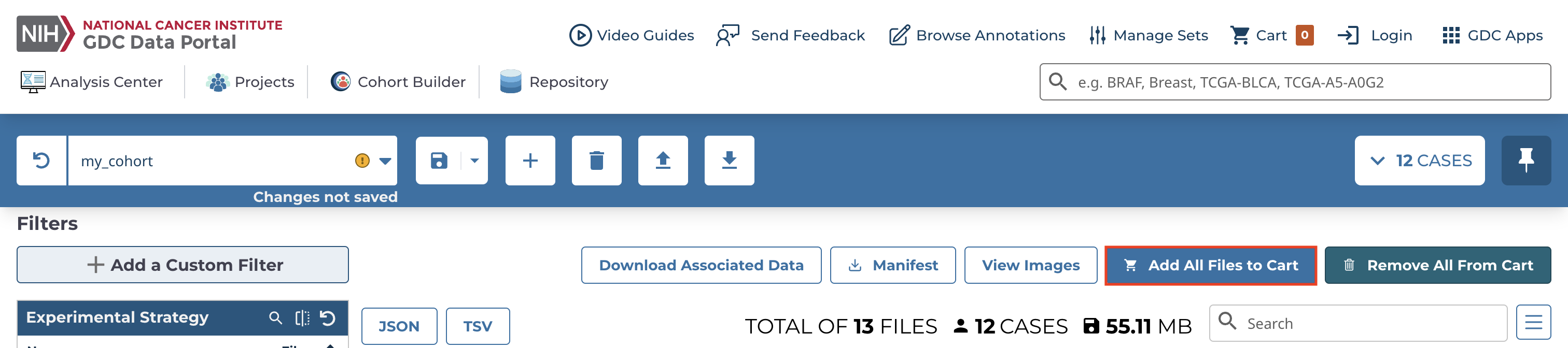
-
Navigate to the "Cart", and select "Download Cart" and "Cart" to download the contents of the cart locally or select "Manifest" to download files using the GDC Data Transfer Tool, which is the recommended method when downloading large numbers of files.
Note
Files can only be downloaded directly from the Data portal using the local download option if the total file size is less than 5 GB and the total numbers of files to be downloaded does not exceed 10,000.
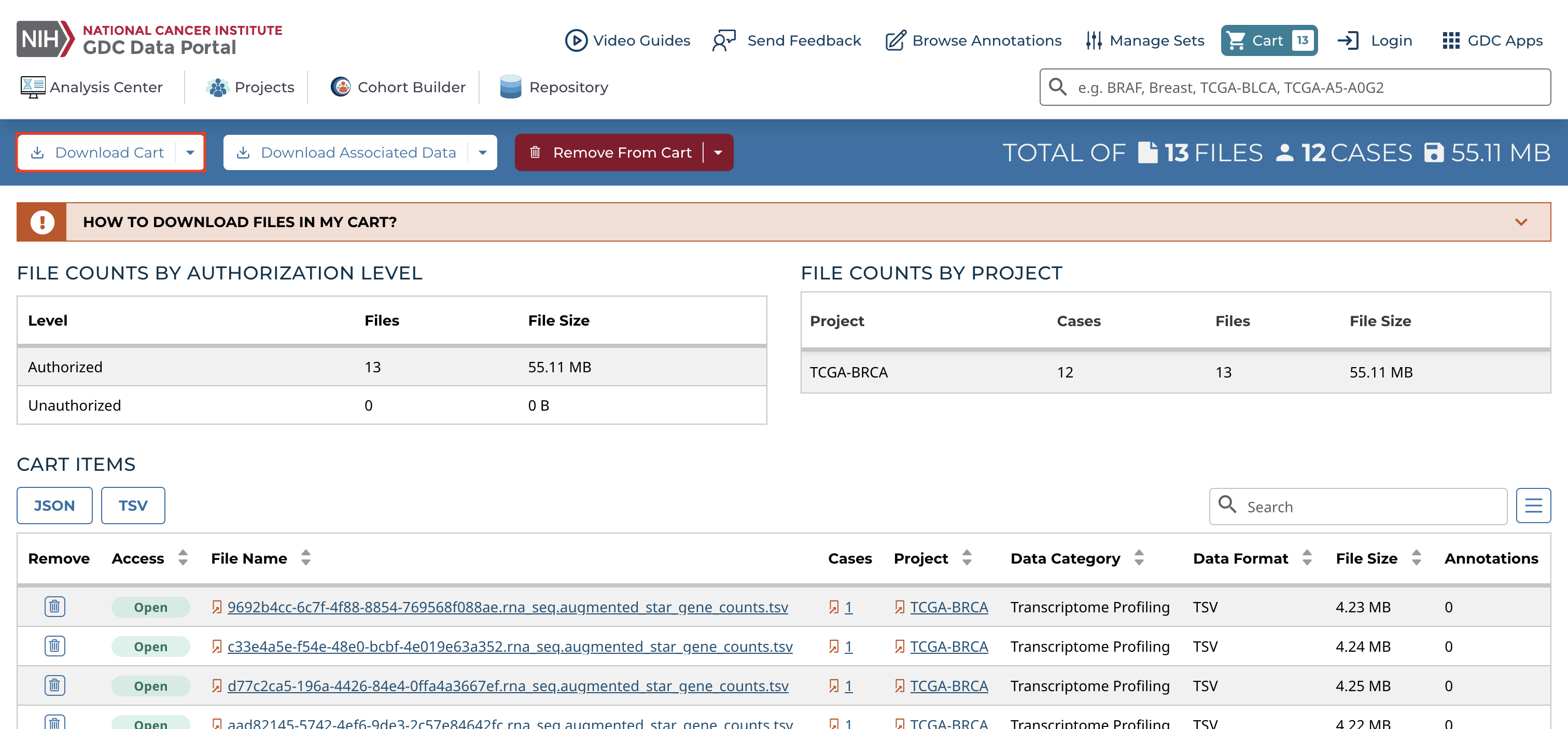
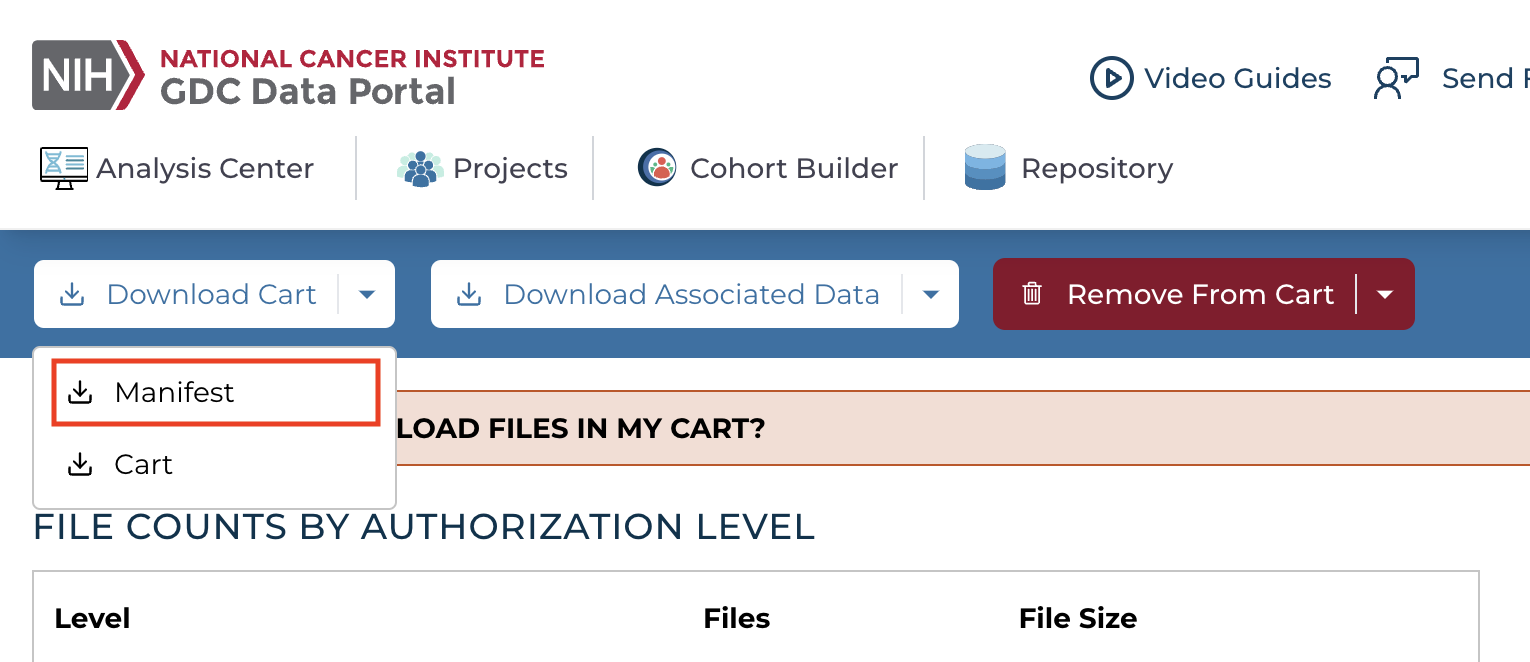
The manifest file contains the Universally Unique Identifier (UUID), MD5 checksum, file size, and file name of each file listed.
The GDC Data Transfer Tool is available in a command line or GUI. You can use whatever version works best for your. The command line client is available for use on Biowulf.
Associated Data:
You will also likely want to download associated data, which includes the following:
Clinical (TSV/JSON) - This includes all clinical information from the cases that are associated with the files, such as data related to patient diagnosis, demographics, exposures, laboratory tests, and family relationships
Biospecimen (TSV/JSON) - This includes all biospecimen information, how a patient's tissue was processed and subsampled, from the cases that are associated with the files.
Sample Sheet - A TSV with commonly-used elements associated with each file, such as sample barcode and sample type.
Metadata This includes all of the metadata associated with each and every file in the cart. Note that this file is only available in JSON format and may take several minutes to download. ---TCGA barcode
The TCGA barcode combines case and biospecimen information for all TCGA samples. See this resource for reading the barcode.
Optional Steps if Using the GDC Data Transfer Tool
Note
This tutorial uses the command line client; to use the Data Transfer GUI, see here. The GDC Application Programming Interface (API) can also be used to search for, download, and submit data and metadata.
Here, I will download the files to Biowulf, the NIH HPC cluster.
You may want to consider using Biowulf if:
- Software is unavailable or difficult to install on your local computer and is available on Biowulf.
- You are working with large amounts of data that can be parallelized to shorten computational time (e.g., Working with millions of sequences).
- You are performing computational tasks that are memory intensive (e.g., whole genome assemblies).
- You are working with large scale data.
Using the GDC Data Transfer Tool on Biowulf
-
Navigate to Helix, the interactive data transfer and file management node for the NIH HPC Systems.
ssh username@helix.nih.gov -
Navigate to your data directory and create a new directory for the data to be transferred.
cd /data/$USER mkdir GDC -
Use the gdc client, command line version of the GDC transfer tool to download the files listed in the manifest.
module load gdc-client gdc-client download -m manifest.txt-m- Download using a manifest file. Replacemanifest.txtwith the name of your manifest file.If you need to access controlled data, you will need to obtain an "Authentication token" and use the
-tflag. See here.Output:
The directory in which the files are downloaded will include folders named by the file UUID. Inside these folders, along with the the data and zipped metadata or index files, will exist a logs folder. The logs folder contains state files that insure that downloads are accurate and allow for resumption of failed or prematurely stopped downloads. While a download is in progress a file will have a .partial extension. This will also remain if a download failed. Once a file is finished downloading the extension will be removed. If an identical manifest is retried another attempt will be made to download files containing a .partial extension. --- GDC documentation
Getting help regarding the GDC
The Genomic Data Commons is well documentated. If you need help, checking the documentation is a good first step.
If you need additional help with accessing, downloading, submitting, or analyzing data in the GDC, contact the GDC help desk at support@nci-gdc.datacommons.io.
There is additional support via training in the form of GDC Webinars, video guides, and a youtube playlist.
Alternative Methods / Platforms for Downloading and Analyzing TCGA Data
Note
This is not an exhaustive list.
-
cBioPortal is a platform for exploratory and interactive visualization, analysis, and download of cancer genomics data.
With cBioPortal
You can quickly view genomic alterations across a set of patients, across a set of cancer types, perform survival analysis and perform group comparisons. If you want to explore specific genes or a pathway of interest in one or more cancer types, the cBioPortal is probably where you want to start....If you want to download raw mRNA expression files or full segmented copy number files, the GDC is probably where you want to start. --- cBioPortal docs
-
Types of analyses:
- pathway analysis options
- cohort exploration
- group comparison
- gene-centric queries
- Patient visualization
-
A local instance can be used to visualize your own data.
-
Contains TCGA data from the Broad Firehose, pan cancer atlas data
- Check out this recent training event brought to you by CBIIT for more information.
-
R Packages
-
-
Access to GDC data through the GDC API
-
Main functions:
GDCquery()- Search the data and return an object with a summary table of results found.GDCdownload()- Use the resulting query to download the data locally.GDCprepare()- Load the downloaded data as asummarizedExperimentobject or data frame.
-
-
- Access to GDAC Firehose
-
-
Python
- Use python to query and download data from the GDC using the GDC API.
-
UCSC Xena https://xenabrowser.net/
- Can work with your own data and large-scale cancer data sets
- Multi-omics data integration / visualization (e.g., gene expression, copy number variation, somatic mutation, etc.) in a side by side format
- TCGA data available:
- Pan-Cancer Atlas project data
- Harmonized GDC data
- UCSC RNA-Seq Compendium (Toil) data
-
Legacy data (originally published data)
Check out this recent training event brought to you by CBIIT for more information.
-
Cloud Platforms
These NCI funded cloud resources allow users to integrate large publicly available cancer genomics datasets (e.g., controlled and open data from TCGA) with their own data and work with bioinformatics tools in a secure cloud environment.
Note
Controlled data will require authorization via dbGAP.
-
Cancer Genomics Cloud (Seven Bridges)
A flexible cloud platform that enables the analysis, storage, and computation of large cancer datasets. The CGC provides a user-friendly portal to access and analyze cancer data where it lives. With the CGC, any user with an account can easily access petabytes of cancer data, share it, analyze and use the computational power of the cloud without having to learn how to program and get familiar with several different data portals. --- Cancer Genomics Cloud
The CGC allows easy access to TCGA data. Both legacy data (data in its original format) and harmonized data (data processed using standardized workflows) are available to access and analyze independently or in combination with your own data using tools available. For a list of available data, see here.
- nice for non-technical users (e.g., those without command line experience)
-
ISB Cancer Gateway in the Cloud (ISB-CGC)
Enables researchers to analyze cloud hosted data including TCGA and TARGET with their own tools as well as with a collection of powerful Google Cloud Platform native tools and technologies including Google BigQuery for big data analytics and Google Compute Engine for complex workflow execution. --- https://datacommons.cancer.gov/analytical-resource/isb-cancer-gateway-cloud
- Better for those with command line experience
- Web application - to create and explore cohorts
- ISB-CGC API - programmatically work with data
- ISB-CGC BigQuery Table Search
- Google Cloud Platform BigQuery Console - view queried tables directly
- ability to interface with R and Python
- Google Compute Engines and VMs - run workflows
- Check out this recent training session for more information.
- Better for those with command line experience
-
Powered by Terra, a secure, scalable cloud-native platform developed by the Broad Institute, Microsoft, and Verily, an Alphabet company. FireCloud provides access to many large NCI-funded datasets including TARGET and TCGA, complemented by a rich collection of other datasets and collaborative projects that are part of the Terra ecosystem, including the Human Cell Atlas, the All of Us Research Program, the AnVIL, and many others. Through FireCloud, researchers can leverage the powerful data analysis functionalities offered by Terra, including its scalable workflow execution system that can handle vast amounts of data processing through automated pipelines, as well as its highly flexible system of customizable cloud environments for interactive analysis and data visualization through preinstalled applications such as Jupyter Notebooks, RStudio, Galaxy, and IGV, and analysis frameworks such as Bioconductor and Hail.
- GUI interface geared toward those with limited command line experience
- Scalable workflows, production ready pipelines
- Facilitates collaboration
- Find out more here.
-