Lesson 2: Navigating file systems with Unix
Quick review
- Unix is an operating system
- We use a unix shell (typically bash) to run many bioinformatics programs
- We need to learn unix to use non-GUI based tools and Biowulf
Lesson Objectives
- Learn the basic structure of a unix command
- Learn how to navigate our file system, including absolute vs relative directories
- Learn unix commands related to navigating directories, creating files and removing files or directories, and getting help
A word about mistakes
YOU WILL MAKE MISTAKES...but, it is okay. We all make mistakes, and mistakes are how we learn.
How can we overcome mistakes?
We practice. The more you use unix and bash scripting the better you will become.
You will need to learn how to troubleshoot error messages. Often this will involve googling the error in reference to the entered command. There are many forums that post help regarding specific errors (e.g., stack overflow, program repositories such as github).
File system
We manage files and directories through the operating system's file system. A directory is synonymous with a "folder", which is used to organize files, other directories, executables, etc.
On a Windows or Mac, we usually open and scroll through our directories and files using a GUI. For example, Finder is the default file management GUI from which we can access files or deploy programs on a macbook.
This same file system can be accessed and navigated via command line from the unix shell.
Some useful unix commands to navigate our file system and tell us some things about our files
pwd(print working directory)ls(list)touch(creates an empty file)nano(basic editor for creating small text files)- using the
rmcommand to remove files. Be careful! mkdir(make a directory) andrmdir(remove a directory, must be empty of all files)cd(change directory), by itself will take you home, cd .. (will take you up one directory), cd /results_dir/exp1 (go directly to this directory)mv(for renaming files or moving files)less(for viewing files, "more" is the older version of this)man(for viewing the man pages when you need help on a command)cp(copy) for copying files
Getting Started
First Unix command (ls)
ls
You may see something like this:
public reads.tar sample.fasta sample.fastq
The "ls" command "lists" the contents of the directory you are in. You may see files and other directories here.
How can you tell the difference between a file and a directory?
We can add some additional options to our command.
ls -lh
will show permissions and indicate directories (d). The -lh are flags. -l refers to listing in long format, while -h provides human readable file sizes.
Or, many systems offset directories and files using colors (e.g., blue for directories). If you don't see colorized output, try the -G flag.
We can also label output by adding a marker to indicate files, directories, links, and executables using the -F flag.
ls -F
/ = directorya
@ = link a
* = executable
Anatomy of a command
Using ls as an example, we can get an idea of the overall structure of a unix command.
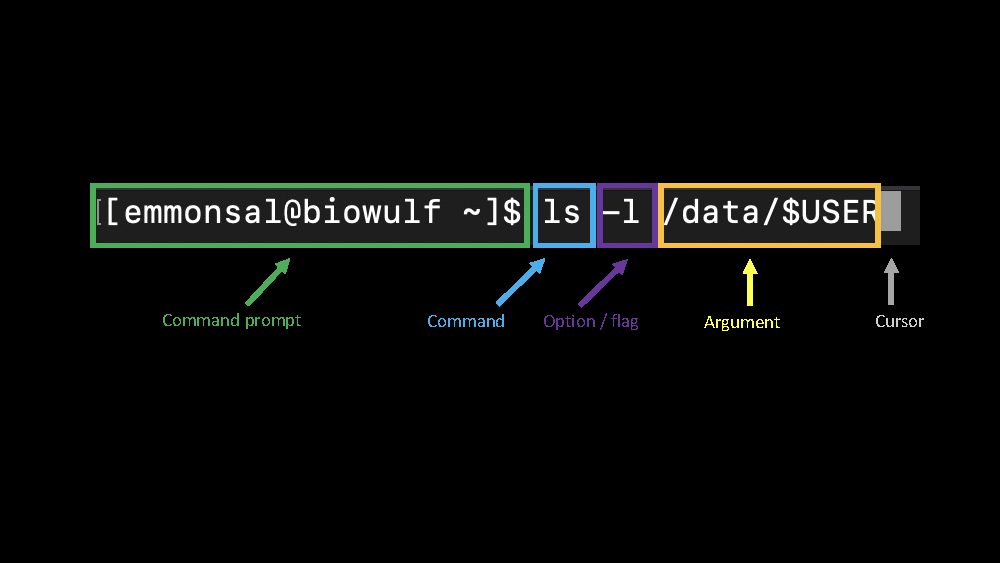
Image inspired by "Learn Enough Command Line to Be Dangerous"
The first thing we see is the command line prompt, usually $ or %, which varies by unix system. The prompt let's us know that the computer is waiting for a command. Next we see the actual command, in this case, ls, telling the computer to list the files and directories. Most commands will have various options / flags that can be included to modify the command function. We can also supply an argument, which in the case of ls is optional. For example, here we supplied an alternative directory from which we are interested in listing files and directories. We hit enter after each command, and when the command has finished running, the command prompt will reappear prompting us to enter more commands.
Where am I? (pwd)
pwd
You should see something like this.
/home/username
where username is your name. This is your home directory - where you start from when you open a terminal. This is an example of a "path". The path tells us the location of a file or directory. Note: while Windows computers use a \ as a path separator, unix systems use a /.
Therefore, the pwd command is very helpful for figuring out where you are in the directory structure. If you are getting "file not found" errors while trying to run something, it is a good idea to pwd and see if you are where you think you are. Type the pwd command and make a note of the directory you are in.
More on the home directory
We see that we are in our home directory. But where is that exactly?
The file system on any computer is hierarchical, with the top level of the file system, or root directory, being /.
See the following example file system:

Image from swcarpentry/shell-novice: Software Carpentry: the UNIX shell, June 2019 (Version v2019.06.1)
At the top is the root directory that holds everything else. We refer to it using a slash character, /, on its own; this character is the leading slash in /Users/nelle.
Inside that directory are several other directories: bin (which is where some built-in programs are stored), data (for miscellaneous data files), Users (where users’ personal directories are located), tmp (for temporary files that don’t need to be stored long-term), and so on.
We know that our current working directory /Users/nelle is stored inside /Users because /Users is the first part of its name. Similarly, we know that /Users is stored inside the root directory / because its name begins with /.
Notice that there are two meanings for the / character. When it appears at the front of a file or directory name, it refers to the root directory. When it appears inside a path, it’s just a separator.
Underneath /Users, we find one directory for each user with an account on Nelle’s machine, her colleagues imhotep and larry.
Like other directories, home directories are sub-directories underneath "/Users" like "/Users/imhotep", "/Users/larry" or "/Users/nelle"
Typically, when you open a new command prompt, you will be in your home directory to start. ---swcarpentry/shell-novice: Software Carpentry: the UNIX shell
Creating files (touch)
The touch command creates a file, but the file is empty, so it is not a command you will use very often, but good to know about.
touch file1.txt
touch file2.txt
ls
Now we see something like this.
file1.txt file2.txt public reads.tar sample.fasta sample.fastq
The nano editor is a text editor useful for small files.
nano file2.txt
Let's put something in this file.
Unix is an operating system, just like Windows or MacOS. Linux is a Unix like operating system; sometimes the names are used interchangeably.
Nano commands for saving your file and exiting nano:
- control O - write file (equivalent to save as)
- File name to write: file2.txt (Hit return/enter on your keyboard to save the file with this name).
- control X - to Exit
This brings us to our next topic which is very important!
Choosing good names for your files and directories.
There should not be spaces in Unix file names or directories. Here is a good method to use:
Use the underscore (_) where a space would go, like this, to name a directory containing RNA-Seq data.
my_RNA_Seq_data
These are examples of file names:
brain_rna.fastq
liver_rna.fastq
The first part of the file name provides info about the file, and the extension (.fastq) tells what kind of file it is. (Examples of file extensions are .csv, .txt, .fastq, .fasta and many more.)
More on file organization to come.
A word about file extensions
It's important to understand file extensions, to know what kinds of data you are working with.
.txt are text files. These are likely but not always tab delimited.
.tsv are tab delimited files.
.csv are "comma-separated values" - good for importing into MS Excel spreadsheets
.tar.gz indicates a tarred and zipped file - so it is a compressed file
.fastq tells you that these are FASTQ files, containing sequence data and quality scores
.fasta indicates FASTA formatted sequence data, either protein or nucleotide
Removing files with rm
Warning - a Unix system will delete something when you ask to delete it and there is usually no way of getting it back.
By adding the -i option, the system will ask if you're sure you want to delete. Generally speaking, when a file on a Unix system is deleted, it is gone.
You can modify your profile on a Unix system to always ask before deleting, this is a good idea when you're just getting started.
rm -i file1.txt
will remove a file we created.
Creating (mkdir) and removing (rmdir) directories
A couple things to note - this is a good time to give your directories meaningful names, which will help you keep things organized. Organization is key. I generally like to have a new directory per project, and within that directory, subdirectories separating raw data from analysis files. From there, each analysis would also get its own subdirectory. However, there are many ways to organize files and you should do whatever makes sense for your data and helps you (and others) stay organized.
For now, let's create a directory called RNA_Seq_data.
mkdir RNA_Seq_data
Removing directories (rmdir)
Directories must be completely empty of all files and other contents before you can delete them. There are ways to "recursively" remove files and directories using the -r option, but these can be dangerous. Keep in mind that once these files are deleted they are gone for good. Be extremely careful with the -r option. As beginners it can be safer to go to the directory and remove contents.
Getting around the Unix directory structure (cd)
This is a very helpful command used for moving around the directory structure.
It can be used to go to a specific directory. Let's "go to" the directory we just made, and make another directory within it.
cd RNA_Seq_data
pwd
mkdir exp_one
ls
cd exp_one
touch myseq.txt
ls
pwd
So, we've moved to the RNA_Seq_data directory, checked our directory with pwd, created a directory called exp_one, listed the contents of RNA_Seq_data so we can see the directory we just created, now we go to that directory with cd, create a file with touch, list the contents with ls and print our working directory.
By itself, the cd command takes you home. Let's try that, and then do a pwd to see where we are.
cd
pwd
We are now in our home directory.
/home/username
How can we go back to the exp_one directory we created? We need to give the "path" to that directory.
cd RNA_Seq_data/exp_one
pwd
ls
Check where you are with pwd and look at the contents of the directory with ls. What do you see? It should be the file "myseq.txt".
Here's another way to get around the directory structure using cd.
cd ~/RNA_Seq_data/exp_one
where the tilde ~ stands for your home directory.
How is this command different from the last one?
cd RNA_Seq_data/exp_one
The first cd command provides the full path to where you want to go, it is called an "absolute" path.
For the second version, you need to be in the directory that contains /RNA_Seq_data, or the command will not work. This is known as a "relative" path.
As a reminder, paths are the sequence of directories that hold your data. In this path...
~/RNA_Seq_data/exp_one
there is a directory named exp_one, within a directory named RNA_Seq_data, within our home directory.
You will become more comfortable with paths as you build up your directories and data.
Another way to use the cd command is to go up one level in the directory structure, like this.
cd ..
This can be very helpful as you move around the directory tree. There are many more ways to use the "cd" command.
Getting back to removing directories (rmdir)
Directories must be completely empty of all files and other contents before you can delete them. There are ways to "recursively" remove file and directories using the -r option, but these can be dangerous. Keep in mind that once these files are deleted they are gone for good. Be extremely careful with the -r option. As beginners it can be safer to go to the directory and remove contents.
What do you see when you try to remove this directory?
rmdir exp_one
What should we do? We need to remove the contents of a directory before we can remove the directory. Here's one safe option.
cd exp_one
ls
rm myseq.txt
ls
cd ..
ls
rmdir exp_one
Moving and renaming files and directories, all with one command (mv)
The mv command is a handy way to rename files if you've created them with a typo or decide to use a more descriptive name. For example:
cd
mv file2.txt README.txt
ls
Be careful when moving files, a mistake in the command can yield unexpected results.
mv README.txt RNA_Seq_data
cd RNA_Seq_data
ls
The -i interactive option will help keep you safe.
For example:
mkdir dir1
mkdir dir2
touch dir2/hello.txt
touch hello.txt
mv -i dir2/hello.txt hello.txt
Let's compare the following
mv dir1 dir2
cd dir2
mv dir1 dir3
Viewing file content
We can use the less command to view the contents of a file like this.
cd
less /data/sample.fasta
You'll need to type q to get out of less and back to the command line. Before the less command was available, the more command was commonly used to look at file content. The less command has more options for scrolling through files, so it is now the preferred command.
Copying files (cp)
This is similar to mv but will create an actual copy of a file. You will need to specify what you are copying (the source) and where you want to make the copy (the target).
For example:
Let's make a file in our home directory.
touch ~/file_to_copy.txt
Now, let's move that file to RNA_Seq_data.
cp ~/file_to_copy.txt ./RNA_Seq_data
Remember, the . is a relative path shortcut denoting our current directory.
We can also copy an entire directory using the recursive flag (cp -r).
cp -r RNA_Seq_data RNA_Seq_data_copy
Help! (man)
All Unix commands have a man or "manual" page that describes how to use them. If you need help remembering how to use the command ls, you would type:
man ls
There are quite a few flags/options that we can use with the ls command, and we can learn all about them on the man page. My favorite flags for ls are -l and -h. We will use flags often, and you won't get far in Unix without knowing about them. Try this:
cd
ls -lh
We have already seen these flags, but as a reminder...
-h when used with the -l option, use unit suffixes (Byte, Kilobyte, Megabyte, Gigabyte, Terabyte and Petabyte) in order to reduce the number of digits to three or less using base 2 for sizes.
-l (The lowercase letter "ell".) List in long format. (See below). If the output is to a terminal, a total sum for all the file sizes is output on a line before the long listing.
Compare the results between these two commands.
cd
ls
ls -lh
Additional Resources
Software Carpentry: The Unix Shell
Help Session
Practice navigating the file system and creating files. Instructions are here.